Projet réalisé dans le cadre du Consortium industriel FactoryLab avec les expertises croisées du CEA-List, et du CETIM en collaboration avec Safran, Naval Group, Stellantis et SLB.

Contexte
L’intelligence artificielle (IA) se développe très rapidement et présente de nombreuses opportunités de repenser certaines tâches pour gagner en productivité, en coût ou en fiabilité. Le domaine des contrôles non destructifs, et notamment de la radiographie, ne fait pas exception.
La partie analyse des images de radiographie présente notamment un fort potentiel pour l’IA, et des applications sont déjà en place dans certaines entreprises. Ces applications sont souvent sous forme d’algorithmes d’aide à la sanction, qui mettent en avant les indications pour le contrôleur, et dans certains cas de sanction automatique s’ils ont pu être qualifiés pour l’application de critères d’acceptation en plus de la détection d’indications.
La difficulté majeure dans la mise en place d’un système d’aide à la sanction ou de sanction automatique par IA est de disposer de données suffisantes. En effet, l’entraînement d’un algorithme de détection supervisé (algorithme « standard ») nécessite plusieurs centaines d’images à minima, incluant une bonne diversité de chacun des types d’indications recherchés.
Découlant de ça, l’objectif de ce projet a été d’étudier les solutions possibles pour permettre l’implémentation d’un algorithme de détection d’indications sur des images de radiographie lorsque peu d’images sont disponibles pour l’entraînement d’un algorithme standard. Pour cela, cinq algorithmes ont été entraînés et ont permis de comparer trois approches différentes :
- Algorithme supervisé entraîné sur une base d’images avec des défauts réels annotées manuellement : cet algorithme, qui correspond à la solution standard que l’on retrouve souvent déployée aujourd’hui, a pour but de servir d’étalon de mesure pour les autres approches testées.
- Algorithme supervisé entraîné sur une base d’images hybride, constituée à la fois d’images avec des défauts réels annotées manuellement, et d’images réelles sur lesquelles des défauts artificiels sont implantés par simulation. Cette méthode est une façon de pallier le manque d’images avec défauts. Trois versions ont été testées dans le projet, avec un même algorithme entraîné sur des proportions différentes d’images avec défauts réels et d’images avec des défauts simulés.
- Algorithme de détection d’anomalie (dits « one class ») : ces algorithmes peuvent être entraînés uniquement à partir d’images acceptables, ce qui permet de les mettre en place même sur des applications pour lesquelles il y a très peu d’images de défauts.
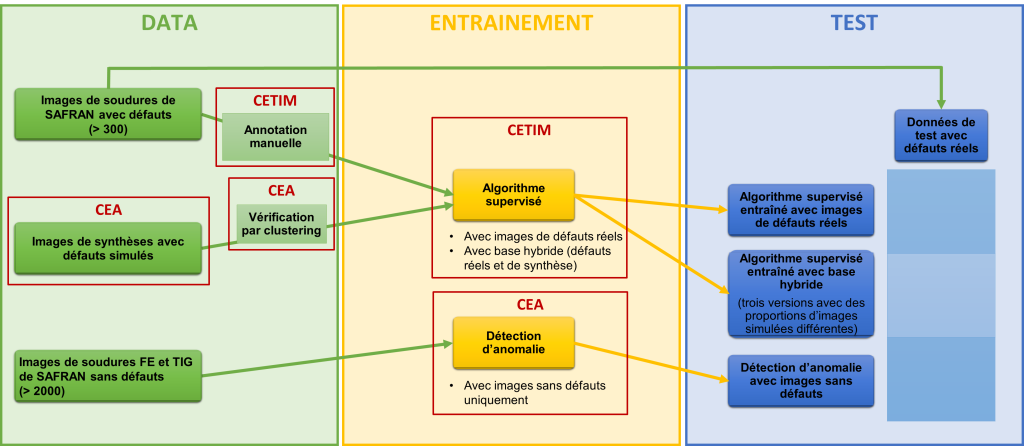
Cas d’usage et étapes du projet
L’étude a été réalisée sur les images numériques de soudures par faisceau d’électrons de chambres de combustion fournies par Safran. Trois types d’indications étaient recherchés : des soufflures isolées, des soufflures groupées et des inclusions de tungstène sur les zones soudées en TIG. Les résultats sont toutefois très limités pour la détection des inclusions de tungstène du fait du manque d’images présentes dans la base de données. Au total, 400 images avec indications et plusieurs milliers d’images saines ont été fournies pour le projet.
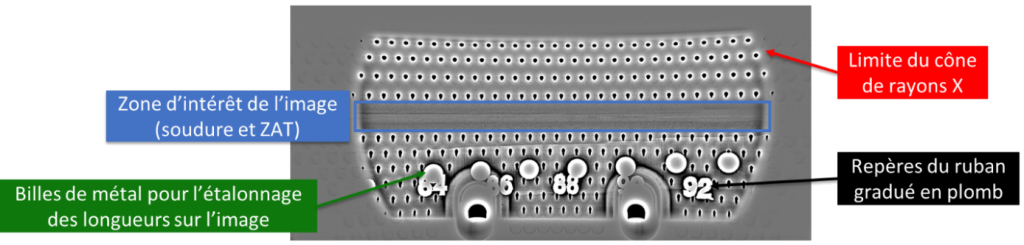
Une annotation manuelle a été réalisée sur l’ensemble des images avec indications pour permettre l’entraînement de l’algorithme standard de référence.
Les images saines ont été utilisées directement pour entraîner l’algorithme de détection d’anomalie, avec une phase de test importante pour déterminer quel algorithme retenir parmi tous ceux disponibles aujourd’hui.
Un millier d’images de synthèse ont été générées en simulant l’absorption des rayons X de soufflures et d’inclusions de tungstène par logiciel dans un modèle de la pièce, et en incluant ces défauts sur des images réelles sans indications. Le même algorithme supervisé a été entraîné, en plus du set d’images avec défauts réels, sur trois sets avec des proportions différentes d’images réelles et d’images de synthèse.

Résultats
Des essais comparatifs ont été réalisés entre les différents algorithmes entraînés sur une base de donnée de défauts réels contenant 185 indications annotées. Les algorithmes ont tous donné des résultats de détection intéressants, avec 62 % des indications importantes détectées par le moins bon algorithme, et jusqu’à 87 % pour l’algorithme le plus performant. Ces résultats sont insuffisants pour remplacer intégralement un contrôle humain sur des applications critiques, mais peuvent suffire pour l’implémentation d’un système d’aide à la sanction.
L’algorithme de détection d’anomalie (entraîné uniquement avec des images sans indications), malgré un nombre plus élevé de faux positifs, a donné les meilleurs résultats, avec notamment un net avantage sur la détection des soufflures isolées. À noter que ce type d’algorithme ne permet pas de classer les indications par nature comme le font les autres algorithmes testés.

Les quatre algorithmes supervisés, dont trois entraînés sur base hybride incluant des images de synthèse, ont conduit à des résultats très similaires globalement, malgré des différences marquées lors de l’observation des annotations image par image.

Conclusions et perspectives
L’étude a mis en évidence la pertinence des deux approches étudiées pour la mise en place de systèmes d’IA dans des cas où les données de départ sont insuffisantes pour l’entraînement d’un algorithme supervisé standard, avec des performances équivalentes voire supérieures pour le cas d’étude retenu par rapport à un algorithme supervisé standard.
Les résultats obtenus dans l’étude pourraient être affinés en testant des cas d’usage différents. La fiabilité des résultats pourrait aussi être confirmée en poursuivant plusieurs pistes détaillées dans le rapport de l’étude (modification de la gestion de l’affichage des images, duplication des entraînements pour vérifier la convergence des résultats…).
Auteur : Nicolas DANKAR, chef de projet AUTO RX, CETIM.